Lock-freedom without garbage collection
TL;DR
It’s widespread folklore that one advantage of garbage collection is the ease of building high-performance lock-free data structures. Manual memory management for these data structures is not easy, and a GC makes it trivial.
This post shows that, using Rust, it’s possible to build a memory management API for concurrent data structures that:
- Makes it as easy to implement lock-free data structures as a GC does;
- Statically safeguards against misuse of the memory management scheme;
- Has overhead competitive with (and more predictable than) GC.
In the benchmarks I show below, Rust is able to easily beat a Java lock-free queue implementation, with an implementation that’s as easy to write.
I’ve implemented “epoch-based memory reclamation” in a new library called Crossbeam, which is ready to use in for your own data structures today. This post covers some background on lock-free data structures, the epoch algorithm, and the entire Rust API.
Contents
Benchmarks
Before looking in depth at the API design and usage for epoch reclamation, let’s cut right to the chase: performance.
To test the overhead my Crossbeam implementation relative to a full GC, I implemented a basic lock-free queue (a vanilla Michael-Scott queue) on top of it, and built the same queue in Scala. In general, JVM-based languages are a good test case for the “good GC” path toward lock-free data structures.
In addition to these implementations, I compared against:
-
A more efficient “segmented” queue that allocates nodes with multiple slots. I wrote this queue in Rust, on top of Crossbeam.
-
A Rust single-threaded queue protected by a mutex.
-
The java.util.concurrent queue implementation (ConcurrentLinkedQueue), which is a tuned variant of the Michael-Scott queue.
I tested these queues in two ways:
-
A multi-producer, single-consumer (MPSC) scenario in which two threads repeatedly send messages and one thread receives them, both in a tight loop.
-
A multi-producer, multi-consumer (MPMC) scenario in which two threads send and two thread receive in a tight loop.
Benchmarks like these are fairly typical for measuring the scalability of a lock-free data structure under “contention” – multiple threads competing to make concurrent updates simultaenously. There are many variations that should be benchmarked when building a production queue implementation; the goal here is just to gauge the ballpark overhead of the memory management scheme.
For the MPSC test, I also compared against the algorithm used in Rust’s built-in channels, which is optimized for this scenario (and hence doesn’t support MPMC).
The machine is a 4 core 2.6Ghz Intel Core i7 with 16GB RAM.
Here are the results, given in nanosecond per message (lower is better):
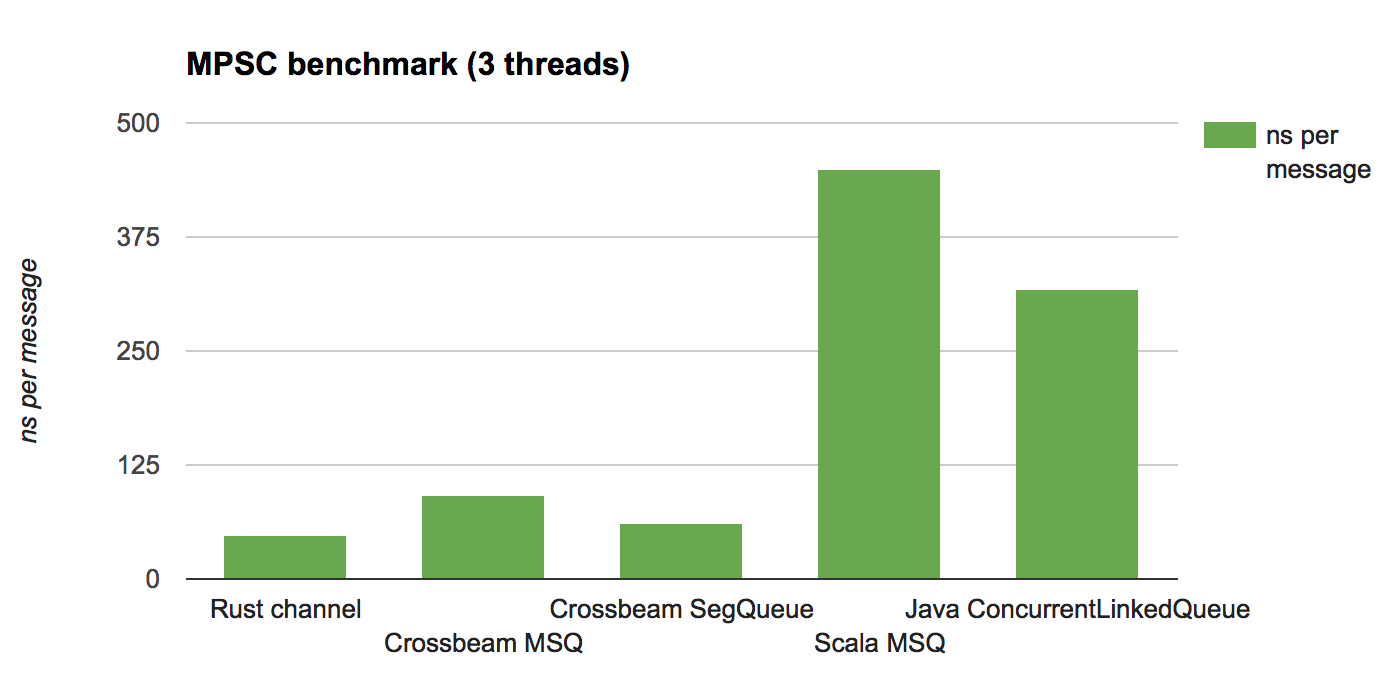
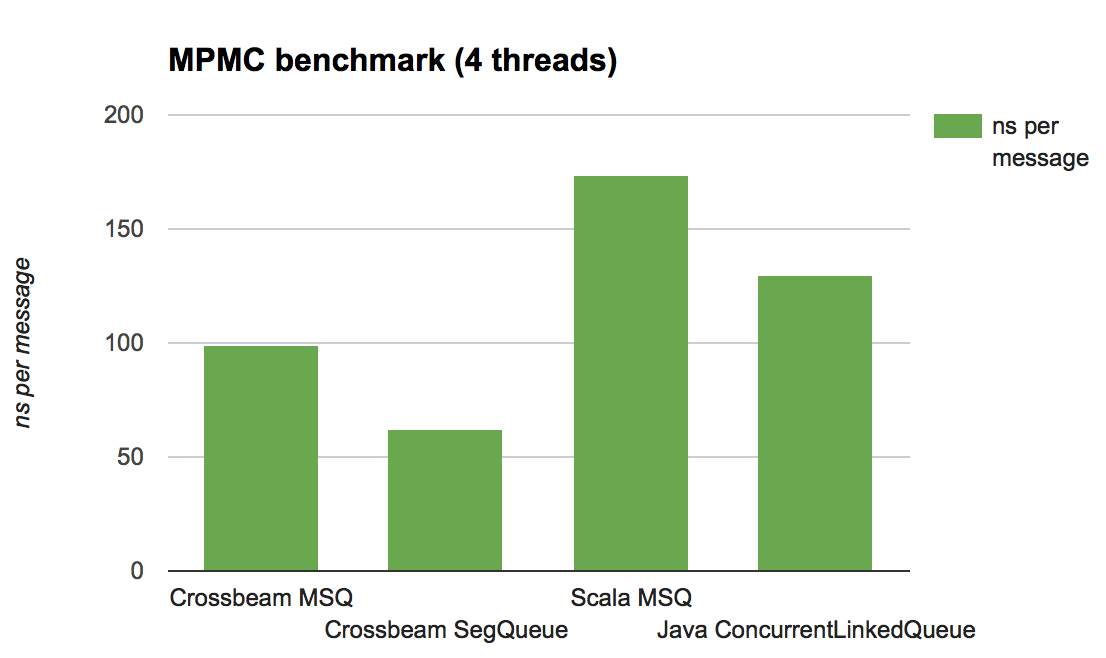
Analysis
The main takeaway is that the Crossbeam implementation – which has not been tuned – is competitive in all cases. It’s possible to do better on both the Rust and JVM sides by using more clever or specialized queues, but these results show at least that the overhead of epochs is reasonable.
Notice that the Java/Scala versions fare much better in the MPMC test than they do in MPSC test. Why is that?
The answer is simple: garbage collection. In the MPSC test, the producers tend to overrun the consumer over time, meaning that the amount of data in the queue slowly grows. That in turn increases the cost of each garbage collection, which involves walking over the live data set.
In the epoch scheme, by contrast, the cost of managing garbage is relatively fixed: it’s proportional to the number of threads, not the amount of live data. This turns out to yield both better and more consistent/predictable performance.
Finally, one comparison I did not include on the chart (because it would dwarf
the others) was using a Mutex around a deque in Rust. For the MPMC test,
performance was around 3040ns/operation, over 20x slower than the Crossbeam
implementation. This is a vivid demonstration of why lock-free data structure
are important – so let’s start by diving into what those are.
Lock-free data structures
When you want to use (and mutate) a data structure from many concurrent threads,
you need synchronization. The simplest solution is a global lock – in Rust,
wrapping the entire data structure in
a Mutex and
calling it a day.
Problem is, that kind of “coarse-grained” synchronization means that multiple threads always need to coordinate when accessing a data structure, even if they were accessing disjoint pieces of it. It also means that even when a thread is only trying to read, it must write, by updating the lock state – and since the lock is a global point of communication, these writes lead to a large amount of cache invalidation traffic. Even if you use a lot of locks at a finer grain, there are other hazards like deadlock and priority inversion, and you often still leave performance on the table.
A more radical alternative is lock-free data structures, which use atomic operations to make direct changes to the data structure without further synchronization. They are often faster, more scalable, and more robust than lock-based designs.
I won’t try to give a full tutorial to lock-free programming in this post, but a key point is that, if you don’t have global synchronization, it’s very difficult to tell when you can free memory. Many published algorithms basically assume a garbage collector or some other means of reclaiming memory. So before lock-free concurrency can really take off in Rust, we need a story for memory reclamation – and that’s what this blog post is all about.
Treiber’s stack
To make things more concrete, let’s look at the “Hello world” of lock-free data
structures: Treiber’s stack. The stack is represented as a singly-linked list,
with all modifications happening on the head pointer:
#![feature(box_raw)]
use std::ptr::{self, null_mut};
use std::sync::atomic::AtomicPtr;
use std::sync::atomic::Ordering::{Relaxed, Release, Acquire};
pub struct Stack<T> {
head: AtomicPtr<Node<T>>,
}
struct Node<T> {
data: T,
next: *mut Node<T>,
}
impl<T> Stack<T> {
pub fn new() -> Stack<T> {
Stack {
head: AtomicPtr::new(null_mut()),
}
}
}
It’s easiest to start with popping. To pop, you just loop, taking a snapshot of
the head and doing a compare-and-swap replacing the snapshot with its next
pointer:
Note that
compare_and_swapatomically changes the value of anAtomicPtrfrom an old value to a new value, if the old value matched. Also, for this post you can safely ignore theAcquire,ReleaseandRelaxedlabels if you’re not familiar with them.
impl<T> Stack<T> {
pub fn pop(&self) -> Option<T> {
loop {
// take a snapshot
let head = self.head.load(Acquire);
// we observed the stack empty
if head == null_mut() {
return None
} else {
let next = unsafe { (*head).next };
// if snapshot is still good, update from `head` to `next`
if self.head.compare_and_swap(head, next, Release) == head {
// extract out the data from the now-unlinked node
// **NOTE**: leaks the node!
return Some(unsafe { ptr::read(&(*head).data) })
}
}
}
}
}
The ptr::read function is Rust’s way of extracting ownership of data without
static or dynamic tracking. Here we are using the atomicity of
compare_and_swap to guarantee that only one thread will call ptr::read –
and as we’ll see, this implementation never frees Nodes, so the destructor on
data is never invoked. Those two facts together make our use of ptr::read
safe.
Pushing is similar:
impl<T> Stack<T> {
pub fn push(&self, t: T) {
// allocate the node, and immediately turn it into a *mut pointer
let n = Box::into_raw(Box::new(Node {
data: t,
next: null_mut(),
}));
loop {
// snapshot current head
let head = self.head.load(Relaxed);
// update `next` pointer with snapshot
unsafe { (*n).next = head; }
// if snapshot is still good, link in new node
if self.head.compare_and_swap(head, n, Release) == head {
break
}
}
}
}
The problem
If we had coded the above in a language with a GC, we’d be done. But as written
in Rust, it leaks memory. In particular, the pop implementation doesn’t
attempt to free the node pointer after it has removed it from the stack.
What would go wrong if we did just that?
// extract out the data from the now-unlinked node
let ret = Some(unsafe { ptr::read(&(*head).data) });
// free the node
mem::drop(Box::from_raw(head));
return ret
The problem is that other threads could also be running pop at the same
time. Those threads could have a snapshot of the current head; nothing would
prevent them from reading (*head).next on that snapshot just after we
deallocate the node they’re pointing to – a use-after-free bug in the making!
So that’s the crux. We want to use lock-free algorithms, but many follow a similar pattern to the stack above, leaving us with no clear point where it’s safe to deallocate a node. What now?
Epoch-based reclamation
There are a few non-GC-based ways of managing memory for lock-free code, but they all come down to the same core observations:
-
There are two sources of reachability at play – the data structure, and the snapshots in threads accessing it. Before we delete a node, we need to know that it cannot be reached in either of these ways.
-
Once a node has been unlinked from the data structure, no new snapshots reaching it will be created.
One of the most elegant and promising reclamation schemes is Keir Fraser’s epoch-based reclamation, which was described in very loose terms in his PhD thesis.
The basic idea is to stash away nodes that have been unlinked from the data structure (the first source of reachability) until they can be safely deleted. Before we can delete a stashed node, we need to know that all threads that were accessing the data structure at the time have finished the operation they were performing. By observation 2 above, that will imply that there are no longer any snapshots left (since no new ones could have been created in the meantime). The hard part is doing all of this without much synchronization. Otherwise, we lose the benefit that lock-freedom was supposed to bring in the first place!
The epoch scheme works by having:
- A global epoch counter (taking on values 0, 1, and 2);
- A global list of garbage for each epoch;
- An “active” flag for each thread;
- An epoch counter for each thread.
The epochs are used to discover when garbage can safely be freed, because no thread can reach it. Unlike traditional GC, this does not require walking through live data; it’s purely a matter of checking epoch counts.
When a thread wants to perform an operation on the data structure, it first sets its “active” flag, and then updates its local epoch to match the global one. If the thread removes a node from the data structure, it adds that node to the garbage list for the current global epoch. (Note: it’s very important that the garbage go into the current global epoch, not the previous local snapshot.) When it completes its operation, it clears the “active” flag.
To try to collect the garbage (which can be done at any point), a thread walks over the flags for all participating threads, and checks whether all active threads are in the current epoch. If so, it can attempt to increment the global epoch (modulo 3). If the increment succeeds, the garbage from two epochs ago can be freed.
Why do we need three epochs? Because “garbage collection” is done concurrently, it’s possible for threads to be in one of two epochs at any time (the “old” one, and the “new” one). But because we check that all active threads are in the old epoch before incrementing it, we are guaranteed that no active threads are in the third epoch.
This scheme is carefully designed so that most of the time, threads touch data that is already in cache or is (usually) thread-local. Only doing “GC” involves changing the global epoch or reading the epochs of other threads. The epoch approach is also algorithm-agnostic, easy to use, and its performance is competitive with other approaches.
It also turns out to be a great match for Rust’s ownership system.
The Rust API
We want the Rust API to reflect the basic principles of epoch-based reclamation:
-
When operating on a shared data structure, a thread must always be in its “active” state.
-
When a thread is active, all data read out of the data structure will remain allocated until the thread becomes inactive.
We’ll leverage Rust’s ownership system – in particular, ownership-based resource management (aka RAII) – to capture these constraints directly in the type signatures of an epoch API. This will in turn help ensure we use epoch management correctly.
Guard
To operate on a lock-free data structure, you first acquire a guard, which is an owned value that represents your thread being active:
pub struct Guard { ... }
pub fn pin() -> Guard;
The pin function marks the thread as active, loads the global epoch, and may
try to perform GC (detailed a bit later in the post). The destructor for
Guard, on the other hand, exits epoch management by marking the thread
inactive.
Since the Guard represents “being active”, a borrow &'a Guard guarantees
that the thread is active for the entire lifetime 'a – exactly what we need
to bound the lifetime of the snapshots taken in a lock-free algorithm.
To put the Guard to use, Crossbeam provides a set of three pointer types meant to work together:
-
Owned<T>, akin toBox<T>, which points to uniquely-owned data that has not yet been published in a concurrent data structure. -
Shared<'a, T>, akin to&'a T, which points to shared data that may or may not be reachable from a data structure, but it guaranteed not to be freed during lifetime'a. -
Atomic<T>, akin tostd::sync::atomic::AtomicPtr, which provides atomic updates to a pointer using theOwnedandSharedtypes, and connects them to aGuard.
We’ll look at each of these in turn.
Owned and Shared pointers
The Owned pointer has an interface nearly identical to Box:
pub struct Owned<T> { ... }
impl<T> Owned<T> {
pub fn new(t: T) -> Owned<T>;
}
impl<T> Deref for Owned<T> {
type Target = T;
...
}
impl<T> DerefMut for Owned<T> { ... }
The Shared<'a, T> pointer is similar to &'a T – it is Copy – but it
dereferences to a &'a T. This is a somewhat hacky way of conveying that the
lifetime of the pointer it provides is in fact 'a.
pub struct Shared<'a, T: 'a> { ... }
impl<'a, T> Copy for Shared<'a, T> { ... }
impl<'a, T> Clone for Shared<'a, T> { ... }
impl<'a, T> Deref for Shared<'a, T> {
type Target = &'a T;
...
}
Unlike Owned, there is no way to create a Shared pointer directly. Instead,
Shared pointers are acquired by reading from an Atomic, as we’ll see
next.
Atomic
The heart of the library is Atomic, which provides atomic access to a
(nullable) pointer, and connects all the other types of the library together:
pub struct Atomic<T> { ... }
impl<T> Atomic<T> {
/// Create a new, null atomic pointer.
pub fn null() -> Atomic<T>;
}
We’ll look at operations one at a time, since the signatures are somewhat subtle.
Loading
First, loading from an Atomic:
impl<T> Atomic<T> {
pub fn load<'a>(&self, ord: Ordering, _: &'a Guard) -> Option<Shared<'a, T>>;
}
In order to perform the load, we must pass in a borrow of a Guard. As
explained above, this is a way of guaranteeing that the thread is active for the
entire lifetime 'a. In return, you get an optional Shared pointer back
(None if the Atomic is currently null), with lifetime tied to the guard.
It’s interesting to compare this to the standard library’s AtomicPtr
interface, where load returns a *mut T. Due to the use of epochs, we’re able
to guarantee safe dereferencing of the pointer within 'a, whereas with
AtomicPtr all bets are off.
Storing
Storing is a bit more complicated because of the multiple pointer types in play.
If we simply want to write an Owned pointer or a null value, we do not even
need the thread to be active. We are just transferring ownership into the data
structure, and don’t need any assurance about the lifetimes of pointers:
impl<T> Atomic<T> {
pub fn store(&self, val: Option<Owned<T>>, ord: Ordering);
}
Sometimes, though, we want to transfer ownership into the data structure and immediately acquire a shared pointer to the transferred data – for example, because we want to add additional links to the same node in the data structure. In that case, we’ll need to tie the lifetime to a guard:
impl<T> Atomic<T> {
pub fn store_and_ref<'a>(&self,
val: Owned<T>,
ord: Ordering,
_: &'a Guard)
-> Shared<'a, T>;
}
Note that the runtime representation of val and the return value is exactly
the same – we’re passing a pointer in, and getting the same pointer out. But
the ownership situation from Rust’s perspective changes radically in this step.
Finally, we can store a shared pointer back into the data structure:
impl<T> Atomic<T> {
pub fn store_shared(&self, val: Option<Shared<T>>, ord: Ordering);
}
This operation does not require a guard, because we’re not learning any new information about the lifetime of a pointer.
CAS
Next we have a similar family of compare-and-set operations. The simplest case
is swapping a Shared pointer with a fresh Owned one:
impl<T> Atomic<T> {
pub fn cas(&self,
old: Option<Shared<T>>,
new: Option<Owned<T>>,
ord: Ordering)
-> Result<(), Option<Owned<T>>>;
}
As with store, this operation does not require a guard; it produces no new
lifetime information. The Result indicates whether the CAS succeeded; if not,
ownership of the new pointer is returned to the caller.
We then have an analog to store_and_ref:
impl<T> Atomic<T> {
pub fn cas_and_ref<'a>(&self,
old: Option<Shared<T>>,
new: Owned<T>,
ord: Ordering,
_: &'a Guard)
-> Result<Shared<'a, T>, Owned<T>>;
In this case, on a successful CAS we acquire a Shared pointer to the data we
inserted.
Finally, we can replace one Shared pointer with another:
impl<T> Atomic<T> {
pub fn cas_shared(&self,
old: Option<Shared<T>>,
new: Option<Shared<T>>,
ord: Ordering)
-> bool;
}
The boolean return value is true when the CAS is successful.
Freeing memory
Of course, all of the above machinery is in service of the ultimate goal:
actually freeing memory that is no longer reachable. When a node has been
de-linked from the data structure, the thread that delinked it can inform its
Guard that the memory should be reclaimed:
impl Guard {
pub unsafe fn unlinked<T>(&self, val: Shared<T>);
}
This operation adds the Shared pointer to the appropriate garbage list,
allowing it to be freed two epochs later.
The operation is unsafe because it is asserting that:
- the
Sharedpointer is not reachable from the data structure, - no other thread will call
unlinkedon it.
Crucially, though, other threads may continue to reference this Shared
pointer; the epoch system will ensure that no threads are doing so by the time
the pointer is actually freed.
There is no particular connection between the lifetime of the Shared pointer
here and the Guard; if we have a reachable Shared pointer, we know that the
guard it came from is active.
Treiber’s stack on epochs
Without further ado, here is the code for Treiber’s stack using the Crossbeam epoch API:
use std::sync::atomic::Ordering::{Acquire, Release, Relaxed};
use std::ptr;
use crossbeam::mem::epoch::{self, Atomic, Owned};
pub struct TreiberStack<T> {
head: Atomic<Node<T>>,
}
struct Node<T> {
data: T,
next: Atomic<Node<T>>,
}
impl<T> TreiberStack<T> {
pub fn new() -> TreiberStack<T> {
TreiberStack {
head: Atomic::new()
}
}
pub fn push(&self, t: T) {
// allocate the node via Owned
let mut n = Owned::new(Node {
data: t,
next: Atomic::new(),
});
// become active
let guard = epoch::pin();
loop {
// snapshot current head
let head = self.head.load(Relaxed, &guard);
// update `next` pointer with snapshot
n.next.store_shared(head, Relaxed);
// if snapshot is still good, link in the new node
match self.head.cas_and_ref(head, n, Release, &guard) {
Ok(_) => return,
Err(owned) => n = owned,
}
}
}
pub fn pop(&self) -> Option<T> {
// become active
let guard = epoch::pin();
loop {
// take a snapshot
match self.head.load(Acquire, &guard) {
// the stack is non-empty
Some(head) => {
// read through the snapshot, *safely*!
let next = head.next.load(Relaxed, &guard);
// if snapshot is still good, update from `head` to `next`
if self.head.cas_shared(Some(head), next, Release) {
unsafe {
// mark the node as unlinked
guard.unlinked(head);
// extract out the data from the now-unlinked node
return Some(ptr::read(&(*head).data))
}
}
}
// we observed the stack empty
None => return None
}
}
}
}
Some obserations:
-
The basic logic of the algorithm is identical to the version that relies on a GC, except that we explicitly flag the popped node as “unlinked”. In general, it’s possible to take lock-free algorithms “off the shelf” (the ones on the shelf generally assume a GC) and code them up directly against Crossbeam in this way.
-
After we take a snapshot, we can dereference it without using
unsafe, because theguardguarantees its liveness. -
The use of
ptr::readhere is justified by our use of compare-and-swap to ensure that only one thread calls it, and the fact that the epoch reclamation scheme does not run destructors, but merely deallocates memory.
The last point about deallocation deserves a bit more comment, so let’s wrap up the API description by talking about garbage.
Managing garbage
The design in Crossbeam treats epoch management as a service shared by all data structures: there is a single static for global epoch state, and a single thread-local for the per-thread state. This makes the epoch API very simple to use, since there’s no per-data structure setup. It also means the (rather trivial) space usage is tied to the number of threads using epochs, not the number of data structures.
One difference in Crossbeam’s implementation from the existing literature on epochs is that each thread keeps local garbage lists. That is, when a thread marks a node as “unlinked” that node is added to some thread-local data, rather than immediately to a global garbage list (which would require additional synchronization).
Each time you call epoch::pin(), the current thread will check whether its
local garbage has surpassed a collection threshold, and if so, it will attempt a
collection. Likewise, whenever you call epoch::pin(), if the global epoch has
advanced past the previous snapshot, the current thread can collect some of its
garbage. Besides avoiding global synchronization around the garbage lists, this
new scheme spreads out the work of actually freeing memory among all the threads
accessing a data structure.
Because GC can only occur if all active threads are on the current epoch, it’s not always possible to collect. But in practice, the garbage on a given thread rarely exceeds the threshold.
There’s one catch, though: because GC can fail, if a thread is exiting, it needs to do something with its garbage. So the Crossbeam implementation also has global garbage lists, which are used as a last-ditch place to throw garbage when a thread exits. These global garbage lists are collected by the thread that successfully increments the global epoch.
Finally, what does it mean to “collect” the garbage? As mentioned above, the library only deallocates the memory; it does not run destructors.
Conceptually, the framework splits up the destruction of an object into two
pieces: destroying/moving out interior data, and deallocating the object
containing it. The former should happen at the same time as invoking unlinked
– that’s the point where there is a unique thread that owns the object in every
sense except the ability to actually deallocate it. The latter happens at some
unknown later point, when the object is known to no longer be referenced. This
does impose an obligation on the user: access through a snapshot should only
read data that will be valid until deallocation. But this is basically always
the case for lock-free data structures, which tend to have a clear split between
data relevant to the container (i.e., Atomic fields), and the actual data
contained (like the data field in Node).
Splitting up the tear down of an object this way means that destructors run
synchronously, at predictable times, alleviating one of the pain points of GC,
and allowing the framework to be used with non-'static (and non-Send) data.
The road ahead
Crossbeam is still in its infancy. The work here is laying the foundation for exploring a wide range of lock-free data structures in Rust, and I hope for Crossbeam to eventually play a role similar to java.util.concurrent for Rust – including a lock-free hashmap, work-stealing deques, and lightweight task engine. If you’re interested in this work, I’d love to have help!