Zero-cost futures in Rust
One of the key gaps in Rust’s ecosystem has been a strong story for fast and productive asynchronous I/O. We have solid foundations, like the mio library, but they’re very low level: you have to wire up state machines and juggle callbacks directly.
We’ve wanted something higher level, with better ergonomics, but also better composability, supporting an ecosystem of asynchronous abstractions that all work together. This story might sound familiar: it’s the same goal that’s led to the introduction of futures (aka promises) in many languages, with some supporting async/await sugar on top.
A major tenet of Rust is the ability to build zero-cost abstractions, and that leads to one additional goal for our async I/O story: ideally, an abstraction like futures should compile down to something equivalent to the state-machine-and-callback-juggling code we’re writing today (with no additional runtime overhead).
Over the past couple of months, Alex Crichton and I have developed a zero-cost futures library for Rust, one that we believe achieves these goals. (Thanks to Carl Lerche, Yehuda Katz, and Nicholas Matsakis for insights along the way.)
Today, we’re excited to kick off a blog series about the new library. This post gives the highlights, a few key ideas, and some preliminary benchmarks. Follow-up posts will showcase how Rust’s features come together in the design of this zero-cost abstraction. And there’s already a tutorial to get you going.
Why async I/O?
Before delving into futures, it’ll be helpful to talk a bit about the past.
Let’s start with a simple piece of I/O you might want to perform: reading a
certain number of bytes from a socket. Rust provides a function,
read_exact,
to do this:
// reads 256 bytes into `my_vec`
socket.read_exact(&mut my_vec[..256]);
Quick quiz: what happens if we haven’t received enough bytes from the socket yet?
In today’s Rust, the answer is that the current thread blocks, sleeping until more bytes are available. But that wasn’t always the case.
Early on, Rust had a “green threading” model, not unlike Go’s. You could spin up
a large number of lightweight tasks, which were then scheduled onto real OS
threads (sometimes called “M:N threading”). In the green threading model, a
function like read_exact blocks the current task, but not the
underlying OS thread; instead, the task scheduler switches to another
task. That’s great, because you can scale up to a very large number of tasks,
most of which are blocked, while using only a small number of OS threads.
The problem is that green threads were at odds with Rust’s ambitions to be a true C replacement, with no imposed runtime system or FFI costs: we were unable to find an implementation strategy that didn’t impose serious global costs. You can read more in the RFC that removed green threading.
So if we want to handle a large number of simultaneous connections, many of which are waiting for I/O, but we want to keep the number of OS threads to a minimum, what else can we do?
Asynchronous I/O is the answer – and in fact, it’s used to implement green threading as well.
In a nutshell, with async I/O you can attempt an I/O operation without blocking. If it can’t complete immediately, you can retry at some later point. To make this work, the OS provides tools like epoll, allowing you to query which of a large set of I/O objects are ready for reading or writing – which is essentially the API that mio provides.
The problem is that there’s a lot of painful work tracking all of the I/O events you’re interested in, and dispatching those to the right callbacks (not to mention programming in a purely callback-driven way). That’s one of the key problems that futures solve.
Futures
So what is a future?
In essence, a future represents a value that might not be ready yet. Usually, the future becomes complete (the value is ready) due to an event happening somewhere else. While we’ve been looking at this from the perspective of basic I/O, you can use a future to represent a wide range of events, e.g.:
A database query that’s executing in a thread pool. When the query finishes, the future is completed, and its value is the result of the query.
An RPC invocation to a server. When the server replies, the future is completed, and its value is the server’s response.
A timeout. When time is up, the future is completed, and its value is just
()(the “unit” value in Rust).A long-running CPU-intensive task, running on a thread pool. When the task finishes, the future is completed, and its value is the return value of the task.
Reading bytes from a socket. When the bytes are ready, the future is completed – and depending on the buffering strategy, the bytes might be returned directly, or written as a side-effect into some existing buffer.
And so on. The point is that futures are applicable to asynchronous events of all shapes and sizes. The asynchrony is reflected in the fact that you get a future right away, without blocking, even though the value the future represents will become ready only at some unknown time in the… future.
In Rust, we represent futures as a trait (i.e., an interface), roughly:
trait Future {
type Item;
// ... lots more elided ...
}
The Item type says what kind of value the future will yield once it’s complete.
Going back to our earlier list of examples, we can write several functions
producing different futures (using
impl syntax):
// Lookup a row in a table by the given id, yielding the row when finished
fn get_row(id: i32) -> impl Future<Item = Row>;
// Makes an RPC call that will yield an i32
fn id_rpc(server: &RpcServer) -> impl Future<Item = i32>;
// Writes an entire string to a TcpStream, yielding back the stream when finished
fn write_string(socket: TcpStream, data: String) -> impl Future<Item = TcpStream>;
All of these functions will return their future immediately, whether or not the event the future represents is complete; the functions are non-blocking.
Things really start getting interesting with futures when you combine them. There are endless ways of doing so, e.g.:
Sequential composition:
f.and_then(|val| some_new_future(val)). Gives you a future that executes the futuref, takes thevalit produces to build another futuresome_new_future(val), and then executes that future.Mapping:
f.map(|val| some_new_value(val)). Gives you a future that executes the futurefand yields the result ofsome_new_value(val).Joining:
f.join(g). Gives you a future that executes the futuresfandgin parallel, and completes when both of them are complete, returning both of their values.Selecting:
f.select(g). Gives you a future that executes the futuresfandgin parallel, and completes when one of them is complete, returning its value and the other future. (Want to add a timeout to any future? Just do aselectof that future and a timeout future!)
As a simple example using the futures above, we might write something like:
id_rpc(&my_server).and_then(|id| {
get_row(id)
}).map(|row| {
json::encode(row)
}).and_then(|encoded| {
write_string(my_socket, encoded)
})
See this code for a more fleshed out example.
This is non-blocking code that moves through several states: first we do an RPC
call to acquire an ID; then we look up the corresponding row; then we encode it
to json; then we write it to a socket. Under the hood, this code will compile
down to an actual state machine which progresses via callbacks (with no
overhead), but we get to write it in a style that’s not far from simple
blocking code. (Rustaceans will note that this story is very similar to
Iterator in the standard library.) Ergonomic, high-level code that compiles
to state-machine-and-callbacks: that’s what we were after!
It’s also worth considering that each of the futures being used here might come from a different library. The futures abstraction allows them to all be combined seamlessly together.
Streams
But wait – there’s more! As you keep pushing on the future “combinators”, you’re able to not just reach parity with simple blocking code, but to do things that can be tricky or painful to write otherwise. To see an example, we’ll need one more concept: streams.
Futures are all about a single value that will eventually be produced, but many event sources naturally produce a stream of values over time. For example, incoming TCP connections or incoming requests on a socket are both naturally streams.
The futures library includes a
Stream trait
as well, which is very similar to futures, but set up to produce a sequence of
values over time. It has a set of combinators, some of which work with
futures. For example, if s is a stream, you can write:
s.and_then(|val| some_future(val))
This code will give you a new stream that works by first pulling a value val
from s, then computing some_future(val) from it, then executing that future
and yielding its value – then doing it all over again to produce the next value
in the stream.
Let’s see a real example:
// Given an `input` I/O object create a stream of requests
let requests = ParseStream::new(input);
// For each request, run our service's `process` function to handle the request
// and generate a response
let responses = requests.and_then(|req| service.process(req));
// Create a new future that'll write out each response to an `output` I/O object
StreamWriter::new(responses, output)
Here, we’ve written the core of a simple server by operating on streams. It’s
not rocket science, but it is a bit exciting to be manipulating values like
responses that represent the entirety of what the server is producing.
Let’s make things more interesting. Assume the protocol is pipelined, i.e., that the client can send additional requests on the socket before hearing back from the ones being processed. We want to actually process the requests sequentially, but there’s an opportunity for some parallelism here: we could read and parse a few requests ahead, while the current request is being processed. Doing so is as easy as inserting one more combinator in the right place:
let requests = ParseStream::new(input);
let responses = requests.map(|req| service.process(req)).buffered(32); // <--
StreamWriter::new(responsesm, output)
The
buffered combinator
takes a stream of futures and buffers it by some fixed amount. Buffering the
stream means that it will eagerly pull out more than the requested number of
items, and stash the resulting futures in a buffer for later processing. In this
case, that means that we will read and parse up to 32 extra requests in parallel,
while running process on the current one.
These are relatively simple examples of using futures and streams, but hopefully they convey some sense of how the combinators can empower you to do very high-level async programming.
Zero cost?
I’ve claimed a few times that our futures library provides a zero-cost abstraction, in that it compiles to something very close to the state machine code you’d write by hand. To make that a bit more concrete:
None of the future combinators impose any allocation. When we do things like chain uses of
and_then, not only are we not allocating, we are in fact building up a bigenumthat represents the state machine. (There is one allocation needed per “task”, which usually works out to one per connection.)When an event arrives, only one dynamic dispatch is required.
There are essentially no imposed synchronization costs; if you want to associate data that lives on your event loop and access it in a single-threaded way from futures, we give you the tools to do so.
And so on. Later blog posts will get into the details of these claims and show how we leverage Rust to get to zero cost.
But the proof is in the pudding. We wrote a simple HTTP server framework, minihttp, which supports pipelining and TLS. This server uses futures at every level of its implementation, from reading bytes off a socket to processing streams of requests. Besides being a pleasant way to write the server, this provides a pretty strong stress test for the overhead of the futures abstraction.
To get a basic assessment of that overhead, we then implemented the TechEmpower “plaintext” benchmark. This microbenchmark tests a “hello world” HTTP server by throwing a huge number of concurrent and pipelined requests at it. Since the “work” that the server is doing to process the requests is trivial, the performance is largely a reflection of the basic overhead of the server framework (and in our case, the futures framework).
TechEmpower is used to compare a very large number of web frameworks across many different languages. We compared minihttp to a few of the top contenders:
rapidoid, a Java framework, which was the top performer in the last round of official benchmarks.
Go, an implementation that uses Go’s standard library’s HTTP support.
fasthttp, a competitor to Go’s standard library.
Here are the results, in number of “Hello world!"s served per second on an 8 core Linux machine:
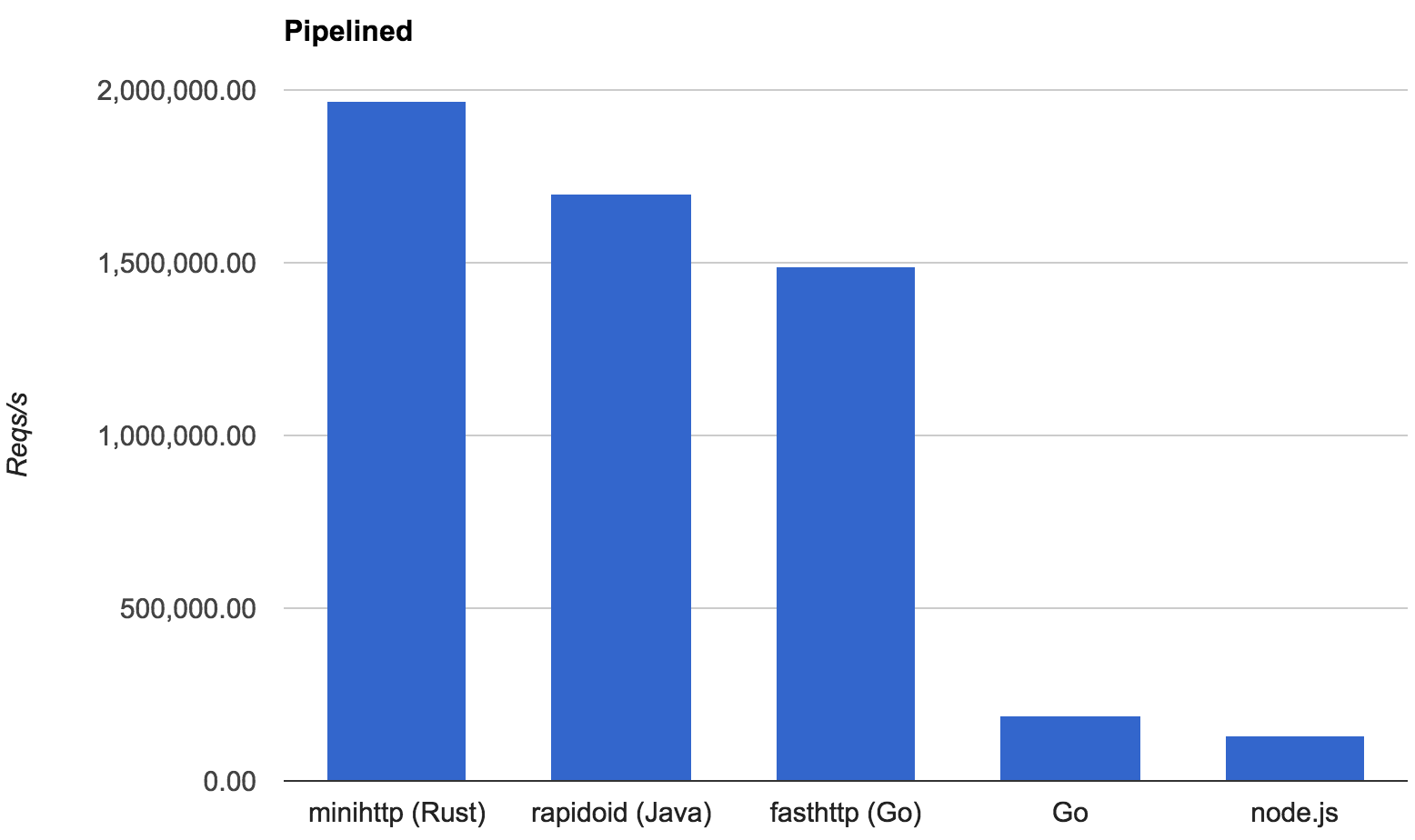
It seems safe to say that futures are not imposing significant overhead.
Update: to provide some extra evidence, we’ve added a comparison of minihttp against a directly-coded state machine version in Rust (see "raw mio” in the link). The two are within 0.3% of each other.
The future
Thus concludes our whirlwind introduction to zero-cost futures in Rust. We’ll see more details about the design in the posts to come.
At this point, the library is quite usable, and pretty thoroughly documented; it comes with a tutorial and plenty of examples, including:
- a simple TCP echo server;
- an efficient SOCKSv5 proxy server;
minihttp, a highly-efficient HTTP server that supports TLS and uses Hyper’s parser;- an example use of minihttp for TLS connections,
as well as a variety of integrations, e.g. a futures-based interface to curl. We’re actively working with several people in the Rust community to integrate with their work; if you’re interested, please reach out to Alex or myself!
If you want to do low-level I/O programming with futures, you can use futures-mio to do so on top of mio. We think this is an exciting direction to take async I/O programming in general in Rust, and follow up posts will go into more detail on the mechanics.
Alternatively, if you just want to speak HTTP, you can work on top of minihttp by providing a service: a function that takes an HTTP request, and returns a future of an HTTP response. This kind of RPC/service abstraction opens the door to writing a lot of reusable “middleware” for servers, and has gotten a lot of traction in Twitter’s Finagle library for Scala; it’s also being used in Facebook’s Wangle library. In the Rust world, there’s already a library called Tokio in the works that builds a general service abstraction on our futures library, and could serve a role similar to Finagle.
There’s an enormous amount of work ahead:
First off, we’re eager to hear feedback on the core future and stream abstractions, and there are some specific design details for some combinators we’re unsure about.
Second, while we’ve built a number of future abstractions around basic I/O concepts, there’s definitely more room to explore, and we’d appreciate help exploring it.
More broadly, there are endless futures “bindings” for various libraries (both in C and in Rust) to write; if you’ve got a library you’d like futures bindings for, we’re excited to help!
Thinking more long term, an obvious eventual step would be to explore
async/awaitnotation on top of futures, perhaps in the same way as proposed in Javascript. But we want to gain more experience using futures directly as a library, first, before considering such a step.
Whatever your interests might be, we’d love to hear from you – we’re acrichto
and aturon on Rust’s
IRC channels. Come say hi!